一、Linux容器综述
容器技术是Linux系统虚拟化演进的成果,是在操作系统层面上实现的一种轻量级的虚拟化隔离方案。旨在单一Linux主机上提供多套隔离的Linux环境,通过将应用程序及其依赖项进行标准封装,打包在一起,运行在容器沙盒中,与其他的容器沙盒相互隔离,形成一个独立、可移植的运行环境,实现在一台Linux主机上运行多个相互隔离的应用程序,提升了资源的使用效率。
相较于传统的虚拟化技术,如VMWare、OpenStack,其是面向资源的封装,虚拟机会部署一个完整的操作系统,提供一整套完整的、隔离的操作系统环境,容器提供了一种更为轻量(共享主机系统内核)、快速(本质是一个个资源隔离、受限的系统进程)、便捷(沙盒可以快速迁移到其他主机)的虚拟化方案,侧重解决的是应用运行时环境隔离的问题,容器需要运行时隔离技术来保证容器的运行环境符合预期,这种软隔离同时也提升了资源利用率,减少了不必要的资源消耗。
本质上,Linux容器是操作系统上的一个特殊进程,通过Cgroups和Namespace等技术,实现了进程级别的隔离和资源控制,从而为应用进程提供了一个稳定、可靠、相对安全的运行环境。由于受限Linux容器进程共享内核的特性,内核属性的变动会影响所有的上层容器进程,同时软隔离的属性也会影响容器进程之间的安全性,为了解决这类问题,目前也出现了一些安全容器,如Kata Containers,这类容器应用提供了一个完整的操作系统执行环境,每个容器都运行在一个单独的微型虚拟机中,拥有独立的操作系统内核,以及虚拟化层的安全隔离。
容器技术的起源可以追溯到20世纪70年代末,当时的Unix v7系统支持chroot(通过修改根目录把用户jail到一个特定目录下),提供了一种简单的隔离模式,chroot内部的文件系统无法访问外部的内容,从而为应用构建一个独立的虚拟文件系统视图。此后,容器技术经历了一系列的演变和发展。
1979年,Unix v7系统支持chroot,为应用构建一个独立的虚拟文件系统视图。
1999年,FreeBSD 4.0支持jail,这是第一个商用化的OS虚拟化技术。
2004年,Solaris 10支持Solaris Zone,这是第二个商用化的OS虚拟化技术。
2005年,OpenVZ发布,这是一个非常重要的Linux OS虚拟化技术先行者。
2004~2007年,Google内部大规模使用Cgroups等OS虚拟化技术。
2006年,Google开源内部使用的process container技术,后续更名为Cgroup。
2008年,Cgroups进入了Linux内核主线。
2008年,LXC(Linux Container)项目具备了Linux容器的雏型。
2011年,CloudFoundry开发Warden系统,它是一个完整的容器管理系统雏型。
2013年,Docker项目正式发布,让Linux容器技术逐步席卷天下。
2014年,Kubernetes项目正式发布,容器技术开始和编排系统起头并进。
2015年,由Google、Redhat、Microsoft及一些大型云厂商共同创立了CNCF(云原生计算基金会),云原生浪潮启动。
容器技术的发展是一个持续不断演进的过程,充满了创新和挑战,从最初的chroot技术,到现在的Docker、Kubernetes等主流容器技术,容器技术的发展始终围绕着提升应用交付效率、简化运维管理、降低资源消耗等目标进行。
二、容器技术原理
OS通过将应用程序运行过程抽象为进程来管理任务的执行,每个进程都有独立的地址空间和执行上下文,这意味着OS通过进程方式对任务程序实现了CPU和内存层面的虚拟化隔离。但是进程之间仍然共享了如文件系统、网络协议栈和IPC等系统资源,导致了资源争抢和相互之间的干扰。Linux的OS层面虚拟化技术在进程隔离的基础上更进一步,对文件系统、网络协议栈、IPC、进程ID、用户ID等OS资源做了进一步隔离,为每一组进程实例构造出一个独立的运行隔离环境,也即容器运行环境,容器解决了进程隔离运行的三个方面的问题,其中通过Linux namespace 资源隔离机制为进程组实现独立资源视图的问题,Cgroup资源控制机制实现了进程组资源访问控制的问题,Capabilities、Apparmor、seccomp 等机制则实现OS对进程组的安全防护问题。
2.1 Cgroups资源控制
Cgroups是Linux内核提供的一种资源管理机制,用于限制、记录和隔离进程组的资源使用情况。Cgroups通过将进程划分为不同的组来进行管理,每个组被称为一个控制组(cgroup),Cgroups使用子系统(subsystem)来描述所能控制的系统资源,如cpu、memory、blkio等,子系统具有多种类型,每个类型的子系统都代表一种系统资源,对某种资源的具体控制,由对应的subsystem来实现。同时Cgroups也提供了丰富的统计和报告功能,可以监控各个控制组的资源使用情况,如CPU使用率、内存使用量、磁盘I/O带宽等
Cgroups实现了一套虚拟文件系统Cgroup fs,作为进行分组管理和各子系统设置的用户接口,它以文件和目录的方式将所控制的子系统资源组织在操作系统的/sys/fs/cgroup路径下,可以通过创建目录和挂载子系统来定义资源的访问权限和控制策略。
可以使用使用mount -t cgroup指令显示cgroups各个子系统挂载的路径:
上图是Linux4.3版本的显示结果,可以看到在/sys/fs/cgroup下面有很多blkio、menory、cpu、cpuset这样的子目录,称作为cgroups子系统,这些是可以被cgroups限制的资源类别,支持的Cgroups子系统限制的资源种类有:
CPU 子系统:限制进程的 CPU 使用;
Memory 子系统:限制进程的内存使用;
Blkio 子系统:限制进程的块设备 IO;
Devices 子系统:控制进程能够访问的设备;
Net_cls 子系统:提供对网络带宽的访问限制,比如对发送带宽和接收带宽进行限制,配合 tc 模块进行流量控制;
Freezer 子系统:进程组中的所有进程挂起;
Pids 子系统:限制 cgroup 中可以创建的进程数。
这里以cpu子系统为例,进入cpu子目录可以看到各类配置文件,通过配置这些文件可以控制进程对cpu相关资源的使用限制。
这几个配置文件的作用如下:
tasks文件:配置受该cgroups子系统控制的进程ID;
cpu.cfs_period_us和cpu.cfs_quota_us文件:cfs_period_us和cfs_quota_us这两个参数组合使用,可用于限制进程在长度为cfs_period的周期内只能被分配到总量为cfs_quota的cpu时间,比如cfs_period_us=10000 & cfs_quota_us=20000 则表示该进程组最多只能使用0.5核cpu;
cpu.shares:是一个权重值,表示进程获取CPU使用时间的相对值。权重越高,进程在竞争CPU资源时获得的比例越高。;
cpu.stat:提供了关于cgroup内的进程使用的CPU时间的统计信息。包括以下几个关键字段:nr_periods(经过的周期数),nr_throttled(被节制的周期数),throttled_time(被节制的总时间)。
只需要在/sys/fs/cgroup文件夹创建新目录的方式就可以创建一个新的CPU控制组,注意控制组之间是有层级关系的,比如下图中docker控制组下又有2个子控制组(具体容器的控制组),子控制组会默认继承docker控制组的属性:
可以看到docker下的 f70d37ff 控制组控制了以下几个进程的cpu资源使用: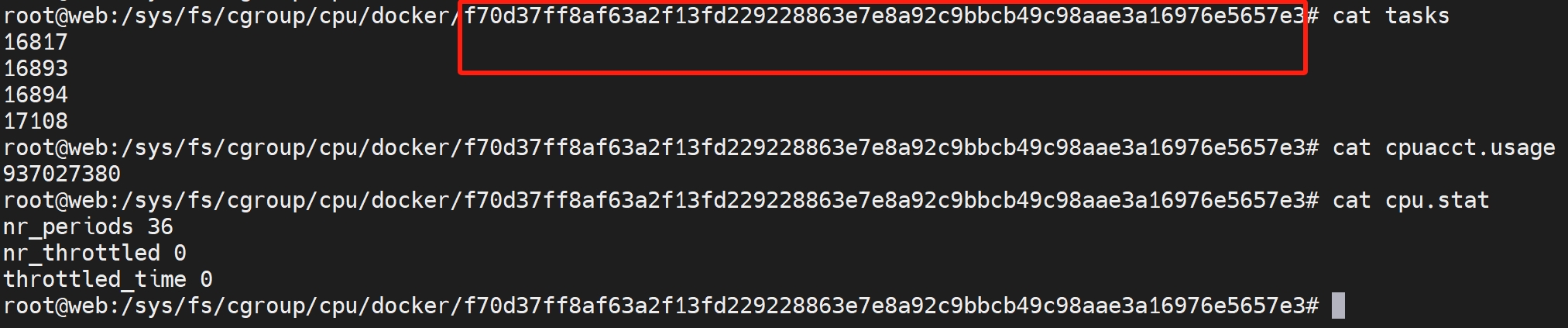
2.2 NameSpaces资源隔离
Linux Namespace是Linux提供的一种内核级别环境隔离的方法,Namespace将全局系统资源封装在一个抽象中,允许将系统资源(如进程、文件系统、网络等)划分到不同的Namespace中,每个Namespace内的进程认为自己具有独立的资源实例,改变一个Namespace中的系统资源只会影响当前Namespace里的进程,对其他Namespace中的进程没有影响,从而实现了资源隔离效果;Linux内核在启动时会创建某一资源的默认 Namespace;没有显示的加入到其他ns中的进程都会在默认的ns中。
Linux Namespaces提供以下几种资源类型的隔离:
| 分类 | 系统调用参数 | 作用 |
|---|---|---|
| Mount namespaces | CLONE_NEWNS | 在不同的Mount namespaces中,进程可以看到不同的文件系统层次结构 |
| PID namespaces | CLONE_NEWPID | 在不同的PID namespaces中,进程有自己的PID空间,允许在每个命名空间中都有一个PID为1的进程 |
| Network namespaces | CLONE_NEWNET | 隔离网络接口,网络协议栈,网络端口等 |
| IPC namespaces | CLONE_NEWIPC | 隔离对IPC的访问,例如消息队列、信号量等 |
| UTS namespaces | CLONE_NEWUTS | 隔离主机名和域名 |
| User namespaces | CLONE_NEWUSER | 隔离用户和用户组ID,允许在用户空间转换用户ID和组ID |
如下图,可以看到Docker引擎启动的容器进程和系统Systemd进程就是在不同的ns中,这些容器进程看到的是独立于宿主机默认ns的资源视图:
Linux中不管是进程还是线程都是task_struct结构体来描述的,在进程结构体中,包含了一个指向Namespace结构体的指针nsproxy,这个用于指明每个进程的所处的ns,ns不同,看到的资源视图也不一样:
1 | struct task_struct { |
nsproxy是定义namespace的结构体,结构体的定义:
1 | /* |
如上代码注释写到,只要namespace被clone了,那么nsproxy就会跟着被clone,默认会继承父进程的ns。nsproxy结构提的变量定义:
‘count’ 是task引用namspace的计数,这是通过nsproxy指向的计数。
nsproxy被共用所有namespace的tasks所共享。只要一个namespace被clone或者不被使用,那么nsproxy就会被copy。
uts_namespace结构体主要是包含了运行内核的名称、版本、底层体系结构类型等信息。UTS是UNIX Timesharing System的简称。
*ipc_namespace指向保存在struct ipc_namespace中的所有与进程间通信(IPC)有关的信息。
*mnt_namespace指向的是已经装载的文件系统的视图,在struct mnt_namespace中给出。
*pid_ns_for_children指向有关进程ID的信息,由struct pid_namespace提供。
user_ns 这个在新的3.8内核中实现。
struct net_ns包含所有网络相关的命名空间参数。
Linux提供了以下几个系统调用来使创建的进程在一个全新的ns中,也可以使进程脱离某个ns进入新的ns:
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
unshare() : 使某进程脱离某个 namespace;
setns() : 把某进程加入到某个 namespace。
以clone系统调用为例,clone是linux提供的创建新进程的系统调用,几个主要的参入作用如下:
fn 是指向子进程执行主体函数的指针;
child_stack是运行的栈。需要传尾指针,因为栈是反着的;
flag 在clone中可以传入flag参数使进程拥有独立的ns,如传入flags创建新进程同时拥有独立的 Mount Namespace、UTS Namespace和 IPC Namespace,则flags = CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC ;
arg 是函数运行的参数。
2.3 构建一个Linux容器
本质上,Linux容器也是操作系统的一个特殊进程,通过Cgroups和Namespace技术,为应用进程提供了一个稳定、隔离的运行环境。通过手动方式构建一个Linux容器,可以先使用Linux的创建进程的系统调用来创建一个隔离的进程,然后使用Cgroups限制该进程的资源使用。
2.3.1 clone一个隔离的进程
使用clone系统调用,传入flag=CLONE_NEWPID|CLONE_NEWNET 标识来确认隔离的ns,即可创建一个资源隔离的进程:
1 |
|
2.3.2 Cgroup限制进程的资源使用
通过Cgroup限制进程的某一资源使用,创建一个资源控制组,然后将clone的进程id写入到task中即可。以限制cpu资源使用为例,如下:
创建cpu的cgroup控制单元:
mkdir /sys/fs/cgroup/cpu/
向任务控制列表中添加需要被限制的 Pid
echo container_pid >> /sys/fs/cgroup/cpu///tasks
限制该组进程 CPU 总利用率到 20%
echo 20000 > /sys/fs/cgroup/cpu//cpu.cfs_quota_us
通过以上方式,便可手动的创建一个Linux容器,让这个进程拥有隔离的运行环境。
三、容器运行时
通过手动的方式固然可以创建一个Linux容器,也可以看到容器本质上也就是一个进程,通过Linux的系统调用即可完成;但是也看到,这种方式是比较繁琐的,包括如何与这个隔离的进程做交互等,需要进入到这个进程的ns,查看隔离进程的状态、资源占用等都需要通过一系列的系统调用,这种方式繁琐且需要熟悉底层调用,为了简化这种操作,容器运行时就应运而生了。
容器运行时负责运行和管理容器化应用程序的生命周期。同时,应用容器化以后,为了提升可移植性,实现容器的快速迁移,Docker公司提出了容器镜像的概念,标准化了应用介质的交付,镜像的提出极大的助力了容器技术的蓬勃发展;容器镜像(Container Image)是一种轻量级、可移植的软件打包方式,用于将应用程序及其所有的运行时环境、系统库和依赖项打包到一个单一的文件中。这个文件可以被容器化平台(如 Docker)加载和运行,从而实现应用程序的快速部署和执行。
为了实现容器技术的标准化,docker,coreos等公司共同制定的容器运行时规范,称作为OCI规范,主要定义了容器的生命周期管理规范,包含了以下几个部分内容:
1.OCI Runtime Specification:定义了容器运行时的规范,包括容器的生命周期管理、进程隔离、文件系统、网络和资源配置等方面的标准,这个规范旨在确保不同容器运行时之间的互操作性和可移植性;
2.OCI Image Specification:定义了容器镜像的规范,包括镜像格式、镜像层次结构、元数据和签名等方面的标准5。这个规范旨在确保容器镜像的可移植性和互操作性;
3.OCI Runtime和镜像格式:OCI规范定义了容器的Runtime和镜像格式两个核心的规范;
4.镜像组成:一个镜像由四部分组成:Manifest、Image Index (可选)、Layers、Configuration。
根据容器运行时实现方式和功能层级的不同,可以分为低级容器运行时和高级容器运行时:
1.低级容器运行时:低级容器运行时直接与宿主机操作系统打交道,负责在宿主机上创建和管理容器进程。低级容器运行时主要负责执行设置容器 Namespace、Cgroups等基础操作。常见的低级容器运行时包括runc、runv和runsc等。
2.高级容器运行时:高级容器运行时在低级容器运行时的基础上提供了更多的功能和管理工具。包括了应用介质也就是镜容器像的管理,为容器的运行做前提准备。高级容器运行时通常与低级容器运行时结合使用,常见的高级容器运行时有:Docker、containerd等。
四、Docker容器实践
Docker是一个开源的应用容器引擎,它使用Go语言开发,一个旨在帮助开发人员构建、共享和运行容器应用程序的平台。
4.1 构建容器镜像
容器镜像是应用交付的主要介质,镜像是由按层封装好的文件系统和描述镜像的元数据构成的文件系统包,包含应用所需要的系统、环境、配置和应用本身等,镜像作为容器运行的基础,一般可以通过公开的镜像仓库获取或者通过Dockerfile方式构建。
Dockerfile包含了从基础镜像开始,构建最终镜像所需的所有命令。这些命令可以包括复制文件、安装软件包、设置环境变量等。使用docker build命令,Docker可以读取Dockerfile并自动构建出新的镜像。Dockerfile常见指令有:
FROM : 指定基础镜像
WORKDIR : 指定工作目录
COPY : 将文件或者目录从构建上下文复制到容器中(推荐)
ADD : 将文件或者目录从构建上下文复制到容器中,并且会将压缩文件解压缩,支持 URL
RUN : 在容器中执行命令
CMD : 容器启动时执行的命令
EXPOSE : 指定要监听的端口以实现与外部通信
一个简要的Dockerfile示例如下:
1 | FROM nginx:latest |
然后通过build命令构建镜像,运行:
1 | docker build -t nginx . |
4.2 运行容器
通过以上,就可以构建出来一个镜像,然后通过run指令即可运行,可以从一个镜像构建出多个容器:
1 | docker run --cpus=2 --memory=600m -d -p 80:80 nginx |
容器的本质也是一个隔离的进程,上述指令,通过nginx镜像运行了一个容器,施加了cpu和内存的限制,可以通过Docker提供的指令来查看该容器的详细信息,包括容器实际对应的进程:
4.3 调试容器
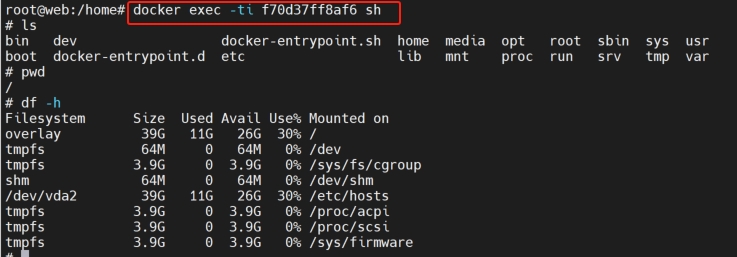
容器运行起来以后,如果需要对容器进行调试,查看状态等,可以使用Docker提供的ps,exec等命令。其中exec可以进到容器里面去,和容器进程处于同一个ns下: